
【行业】深入浅出解析AlphaGo Zero的技术和应用(15页)
2017-11-06
AlphaGo Zero 打败之前所有版本,“左右互搏,天下无双”!10 月18 日GoogleDeepMind 在《Nature》发表了最新版本的AlphaGo Zero 的论文。AlphaGo Zero在进行了3天的自我训练后,在100 局比赛中以100:0击败了上一版本的 AlphaGo——而上一版本的 AlphaGo Lee 击败了曾18 次获得围棋世界冠军的韩国九段棋士李世乭。经过 40 天的自我训练后,AlphaGo Zero 变得更加强大,超越了‚Master‛版本的 AlphaGo——Master 曾击败世界上最优秀的棋士、世界第一的柯洁。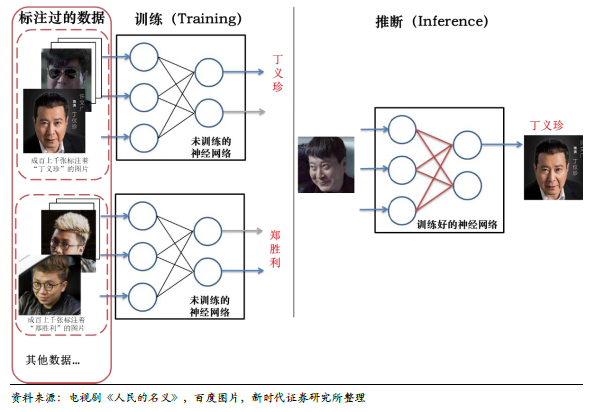
 机器学习可分类为监督学习、非监督学习、强化学习,如何简单理解?下面三图以电视剧《人民的名义》为例,通俗介绍了监督学习(当前最火热、应用范围最大)、非监督学习、强化学习分别是什么。监督学习是当前使用最多的模型,需要有标注的数据录入模型,对模型训练(优化模型的参数),训练的后的模型可以就进行推断了(即应用)。
机器学习可分类为监督学习、非监督学习、强化学习,如何简单理解?下面三图以电视剧《人民的名义》为例,通俗介绍了监督学习(当前最火热、应用范围最大)、非监督学习、强化学习分别是什么。监督学习是当前使用最多的模型,需要有标注的数据录入模型,对模型训练(优化模型的参数),训练的后的模型可以就进行推断了(即应用)。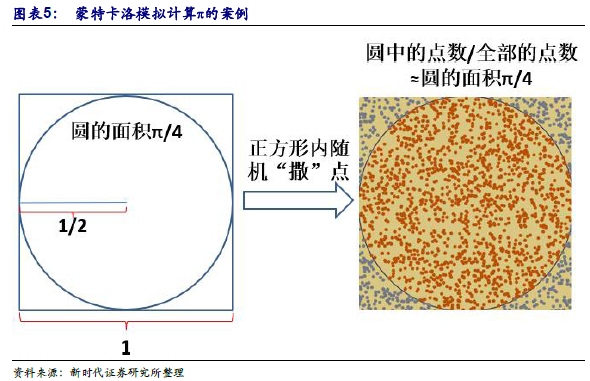
 蒙特卡洛(Monte Calro)模拟是用大量随机样本解决数值的方法——采样越多,越接近最优解。蒙特卡洛模拟通过大量随机样本解决数值问题,是一类方法的统称,诞生于上个世纪40 年代美国的"曼哈顿计划",名字来源于赌城蒙特卡罗,象征概率。简单的案例为计算圆周率π的概率:在一个1×1 的正方形(内臵一个半径1/2 的圆)内撒点,如果点数足够大且均匀分布,那么圆的面积近似于圆中点数/全部点数,由此可计算出圆周率π。
蒙特卡洛(Monte Calro)模拟是用大量随机样本解决数值的方法——采样越多,越接近最优解。蒙特卡洛模拟通过大量随机样本解决数值问题,是一类方法的统称,诞生于上个世纪40 年代美国的"曼哈顿计划",名字来源于赌城蒙特卡罗,象征概率。简单的案例为计算圆周率π的概率:在一个1×1 的正方形(内臵一个半径1/2 的圆)内撒点,如果点数足够大且均匀分布,那么圆的面积近似于圆中点数/全部点数,由此可计算出圆周率π。
机器学习可分类为监督学习、非监督学习、强化学习,如何简单理解?下面三图以电视剧《人民的名义》为例,通俗介绍了监督学习(当前最火热、应用范围最大)、非监督学习、强化学习分别是什么。监督学习是当前使用最多的模型,需要有标注的数据录入模型,对模型训练(优化模型的参数),训练的后的模型可以就进行推断了(即应用)。
蒙特卡洛(Monte Calro)模拟是用大量随机样本解决数值的方法——采样越多,越接近最优解。蒙特卡洛模拟通过大量随机样本解决数值问题,是一类方法的统称,诞生于上个世纪40 年代美国的"曼哈顿计划",名字来源于赌城蒙特卡罗,象征概率。简单的案例为计算圆周率π的概率:在一个1×1 的正方形(内臵一个半径1/2 的圆)内撒点,如果点数足够大且均匀分布,那么圆的面积近似于圆中点数/全部点数,由此可计算出圆周率π。



